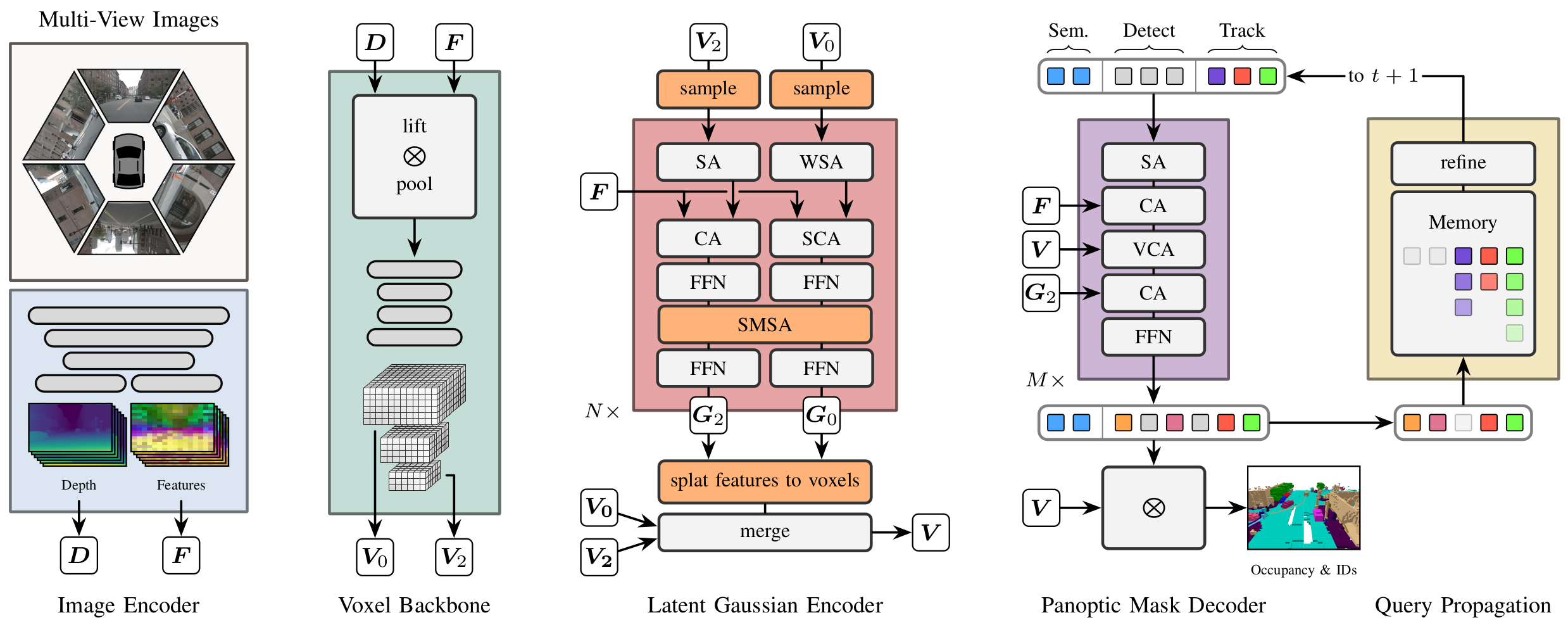
Capturing 4D spatiotemporal scene structure is crucial for the safe and reliable operation of robots in dynamic environments. However, existing approaches typically address only part of the problem: they either provide coarse geometric tracking via bounding boxes or detailed 3D occupancy estimates that lack explicit temporal association and instance-level reasoning. In this work, we present Latent Gaussian Splatting (LaGS) for 4D Panoptic Occupancy Tracking (4D-POT). We revisit the underlying representation and model 3D features as a sparse set of feature-bearing Gaussians. These act as dynamic, volume-oriented keypoints that enable spatially continuous, distance-weighted aggregation of multi-view features before being splatted into a voxel grid for decoding. This point-centric formulation enables flexible, data-dependent receptive fields and long-range spatial interactions that are difficult to capture with local and dense voxel-based operators. A hierarchical Gaussian representation further enables multi-scale reasoning by combining global context from coarse super-points with fine-grained detail from higher-resolution streams. Extensive experiments on Occ3D nuScenes and Waymo demonstrate state-of-the-art performance for 4D-POT.


LaGS
Latent Gaussian Splatting for
4D Panoptic Occupancy Tracking
Maximilian Luz, Rohit Mohan, Thomas Nürnberg, Yakov Miron, Daniele Cattaneo, Abhinav Valada
RA-L 2026